在Sentry對後端的性能監控中,可以看到有以下幾個指標
接下來就簡單聊一下這些指標是什麼、有什麼作用、如何獲取的?
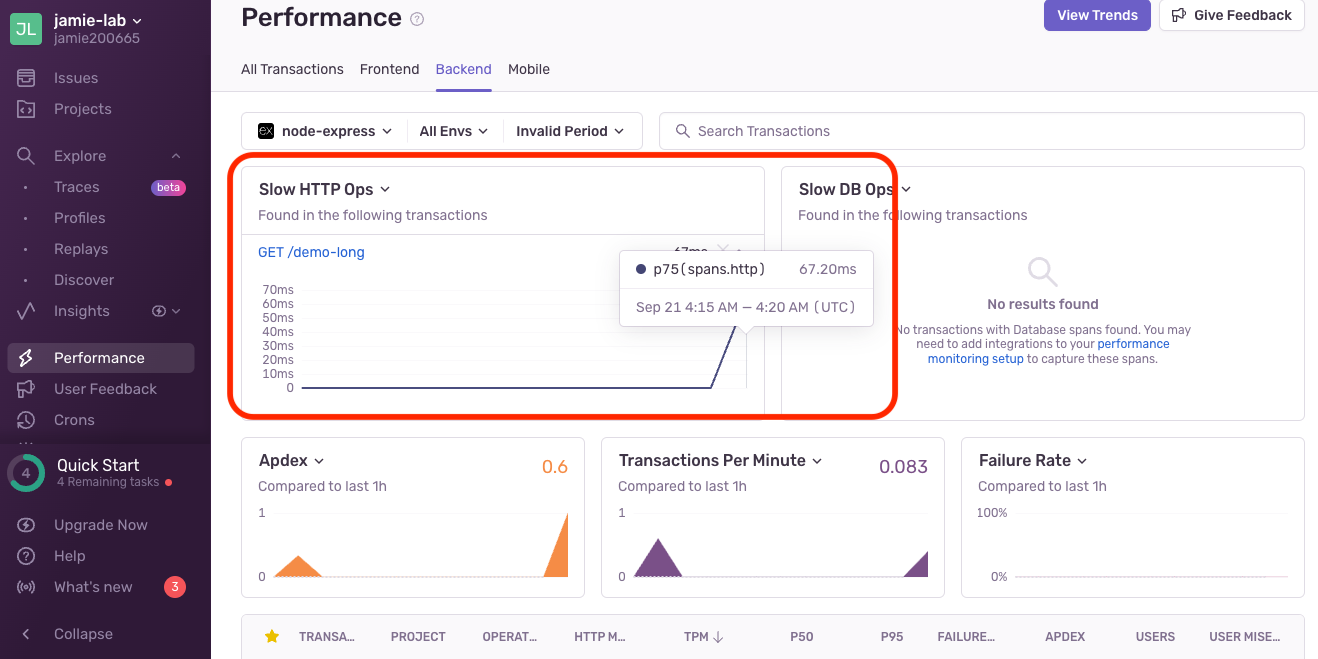
Slow HTTP Operations 是指服務處理 HTTP 請求的速度較慢的操作。這個指標能幫助我們分析哪些 API 或路由可能影響整體應用程式的性能,並找出瓶頸。
例如,一些耗時的第三方 API 呼叫導致 HTTP 操作變慢。Sentry 通常會根據預設的時間閾值來判定哪些操作算是 “slow”。
我們先利用原先的NodeJS Sentry demo,然後在另外寫一個service當作第三方api,以Python FastAPI當作其demo,然後寫一支耗時操作的api:
@app.get("/python-api")
def long_api():
sum = 0
# mock 耗時操作
for i in range(1000000):
sum +=1
return {"message": "python long-service successfully"}
然後再NodeJS中demo看看:
app.get('/demo-long', async (req, res) => {
const data = await axios.get(`${PYTHON_SERVICE_URL}/python-api`);
res.json({ message: 'demo api successfully' });
});
呼叫以後,可以看到Sentry的Slow HTTP Ops面板上已經有記錄:
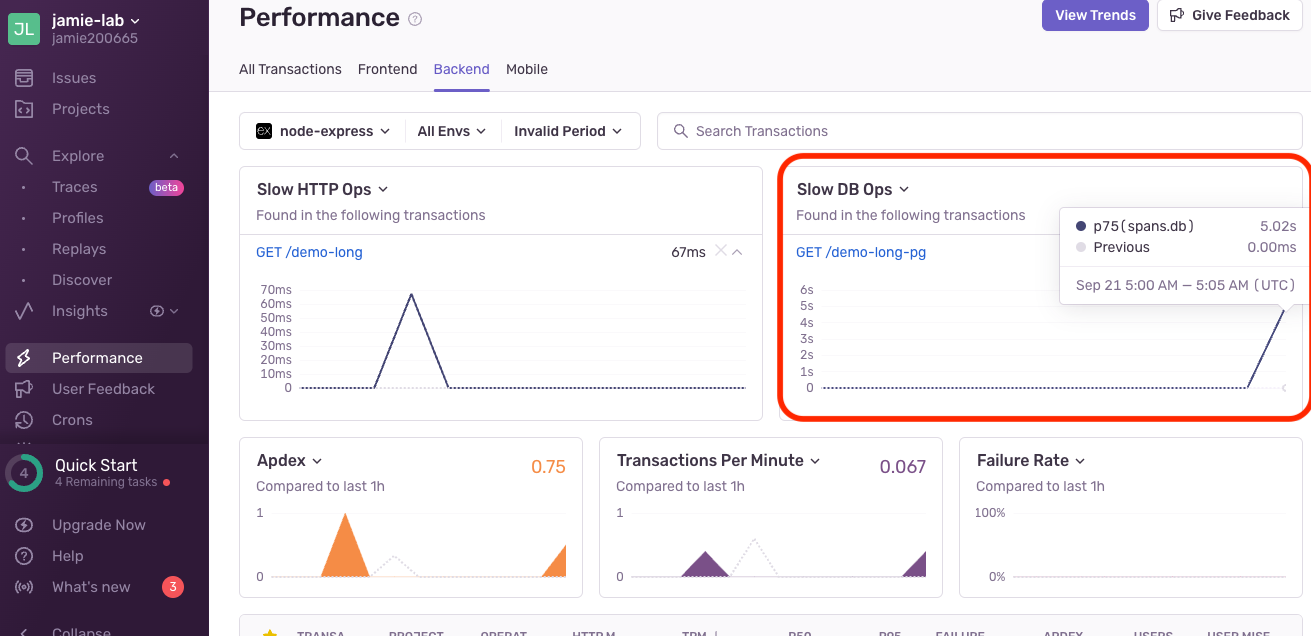
與 Slow HTTP Ops 類似,Slow DB Operations 是指後端在處理資料庫請求時耗時過長的操作。慢速的資料庫操作可能是由於沒有優化的查詢、過大的資料集合或不正確的索引配置引起。
我們以Postgresql為例。而NodeJS的Sentry SDK在初始化的時候,就默認會捕捉pg library對數據庫的操作。
因此,我們可以直接用pg_sleep(5)來demo Postgresql的耗時操作:
app.get('/demo-long-pg', async (req, res) => {
const result = await pgClient.query('SELECT pg_sleep(5);'); // 模擬 5 秒的耗時操作
res.json({ message: 'demo demo-long-pg successfully' });
});
呼叫以後,可以看到Sentry的Slow DB Ops面板上已經有該5秒耗時記錄的操作:
Apdex (Application Performance Index) 是一個根據用戶期望來衡量應用程式滿意度的指標。它會將響應時間分為滿意、可接受和不滿意三個區間,並根據這些區間來計算一個分數。
Transactions Per Minute 如字面上的意義、每分鐘的平均transations,這個指標反映了應用程式處理的請求量和負載狀況。透過這個指標,可以判斷在流量高峰期應用是否有瓶頸,或是否需要進行擴容。
Failure Rate 表示應用在某段時間內失敗請求的比例。當應用的錯誤率增高時,往往意味著存在一些尚未解決的潛在問題,比如系統錯誤、API 呼叫失敗或資料庫異常。Sentry 可以自動追踪這些錯誤,並提供詳細的錯誤上下文幫助解決。
上述三個性能指標(Apdex、Transactions Per Minute、Failure Rate)可以總結為基於 Sentry 收集的 span、issue 進行的數據分析,主要目的在於幫助工程師評估應用的健康狀況和使用者體驗。
Sentry 的性能監控指標提供了多維度的觀察,聚焦於 HTTP 請求和資料庫操作的延遲,以精細化監控應用的運行效能;同時,透過 Apdex 指標來量化用戶滿意度,Transactions Per Minute 反映系統的吞吐量及負載情況,Failure Rate 監測系統穩定性與錯誤頻率。這些指標綜合起來,為開發者提供了全面的數據基礎,從操作層面和用戶體驗層面進行性能分析,幫助更精確地定位瓶頸並優化應用整體表現。
本文的程式碼都可以在此 Github repository上查看。
Apdex (Application Performance Index)
看圖片上面的提示字, 似乎是跟一小時前的數據做比較給出的評比 ?
我只是在想如果是 後端client 自己的檢測, 前一個小時負載很低, 突然這一小時變得超高
例如活動, 搶票等場景. 但上一小時效能表現超好(因為沒人使用咩), 這小時變的不太好, 但使用者還能接受(可能回應時間從100ms 變成600ms, QPS 從20 -> 2000), 只是跟上一小時比是不是就有點不準了. (沒挑毛病, 只是在想如果這場景發生單獨看這指標是不是就有點容易誤判)
嗯嗯的確。像雷N大說的,Apdex 指標在負載變化劇烈的場景(例如活動高峰或搶票)下,可能會失去一些解釋性。這是因為它主要是用來觀察平均情況下使用者的滿意度,沒有考慮負載的劇烈變化的商業情境。這樣可能就需要配合其他指標或者直接自定義事件和閥值來處理惹


 iThome鐵人賽
iThome鐵人賽